Commits on Source (59)
-
dmadmin authored2d45ab0f
-
dmadmin authored
For multinode document, complete a round of edits after first run through following these directions.
05c9b928 -
dmadmin authored
multi-node version. Still need to review for changes needed for multi-node testing.
793bb88c -
 hammonds authored89916e1c
hammonds authored89916e1c -
hammonds authored1be27193
-
hammonds authored35b5e17b
-
hammonds authored
and processing jobs.
0b9c7859 -
hammonds authored
data-storage more consistantly.
b929916a -
 sveseli authored19f8e207
sveseli authored19f8e207 -
dmadmin authored
web pages for individual beamlines. Try to capture some of the info from the web pages plus add in previous document from "user_guide" on dm-station-gui but convert from RST to Markdown.
664f1711 -
dmadmin authored
text.
5daa504a -
dmadmin authored
the location on DS storage when using dm-*-upload command.
0eda3d4d -
sveseli authored8cc393a9
-
sveseli authored65683700
-
sveseli authoredfb006243
-
hammonds authoredad072724
-
hammonds authoreda5caa435
-
hammonds authoredbf5aeaef
-
hammonds authoredd33c1c40
-
hammonds authored27aa835e
-
hammonds authoredb0ce0947
-
hammonds authored451c573c
-
sveseli authoreda547022a
-
hammonds authored
Fix mistakes in scripts to be run to restart. Mixed up monitor & db between the data-storage and the exp-station.
55eed510 -
hammonds authored
2.13.2.
f7ff1e03 -
sveseli authored
ssh
b84b26b7 -
sveseli authored
# Conflicts: # doc/RELEASE_NOTES.txt
2b86e474 -
sveseli authoredb133d343
-
sveseli authoredfd51c130
-
sveseli authored8ee4e150
-
sveseli authoreddfa3cdc5
-
sveseli authored59343932
-
hammonds authored7f61eac2
-
sveseli authored922034a3
-
sveseli authored27e76ee0
-
sveseli authoredd41fe0b4
-
sveseli authored
# Conflicts: # doc/RELEASE_NOTES.txt
70dca8de -
hammonds authored
Rsync SSH Key Enhancements See merge request DM/data-management!8
c9e93dfc -
hammonds authored26e4ac6b
-
-
hammonds authored8c9a2ce9
-
hammonds authorede914a553
-
-
Hannah Parraga authored40310696
-
Hannah Parraga authored3e23e937
-
Hannah Parraga authored5f5725c5
-
-
 hparraga authoredad55701e
hparraga authoredad55701e -
-
hparraga authoredac06f75f
-
hparraga authored7791d5a7
-
hparraga authored05bc7e28
-
hparraga authored1fe6c0fb
-
hparraga authored45aed14f
-
-
hparraga authored4ed0b85d
-
-

-


Showing
- ApsComputingAndDataManagamentInfrastructure-20200210.pdf 0 additions, 0 deletionsApsComputingAndDataManagamentInfrastructure-20200210.pdf
- ApsDataManagementSystem-2019.12.11.pdf 0 additions, 0 deletionsApsDataManagementSystem-2019.12.11.pdf
- Installation/APSDeveloperInstallation.md 0 additions, 213 deletionsInstallation/APSDeveloperInstallation.md
- Installation/APSSectorDeployment.md 0 additions, 1 deletionInstallation/APSSectorDeployment.md
- Installation/DataManagementSplitSystemSetup.md 0 additions, 126 deletionsInstallation/DataManagementSplitSystemSetup.md
- Installation/images/firewall-setup.png 0 additions, 0 deletionsInstallation/images/firewall-setup.png
- Installation/images/typical_install_dir.png 0 additions, 0 deletionsInstallation/images/typical_install_dir.png
- Makefile 0 additions, 6 deletionsMakefile
- RELEASE_NOTES.txt 46 additions, 1 deletionRELEASE_NOTES.txt
- beamline_names.txt 2 additions, 0 deletionsbeamline_names.txt
- demo/apsu-20150709/demo_notes.sv.txt 0 additions, 219 deletionsdemo/apsu-20150709/demo_notes.sv.txt
- demo/apsu-20150709/machine_prep_notes.sv.txt 0 additions, 147 deletionsdemo/apsu-20150709/machine_prep_notes.sv.txt
- demo/sdm-20150716/demo_notes.sv.txt 0 additions, 159 deletionsdemo/sdm-20150716/demo_notes.sv.txt
- demo/sdm-20150716/machine_prep_notes.sv.txt 0 additions, 147 deletionsdemo/sdm-20150716/machine_prep_notes.sv.txt
- demo/sprint-20150421/demo_notes.sv.txt 0 additions, 209 deletionsdemo/sprint-20150421/demo_notes.sv.txt
- demo/sprint-20150630/demo_notes.sv.txt 0 additions, 253 deletionsdemo/sprint-20150630/demo_notes.sv.txt
- dm_test_system_deployment_notes.txt 0 additions, 42 deletionsdm_test_system_deployment_notes.txt
- getting_started/getting-started.md 2 additions, 0 deletionsgetting_started/getting-started.md
- getting_started/gettingDataFromGlobus.md 2 additions, 0 deletionsgetting_started/gettingDataFromGlobus.md
- sphinx/Makefile 0 additions, 20 deletionssphinx/Makefile
File added
ApsDataManagementSystem-2019.12.11.pdf
0 → 100644
File added
Installation/APSSectorDeployment.md
deleted
100644 → 0
{kind=link}
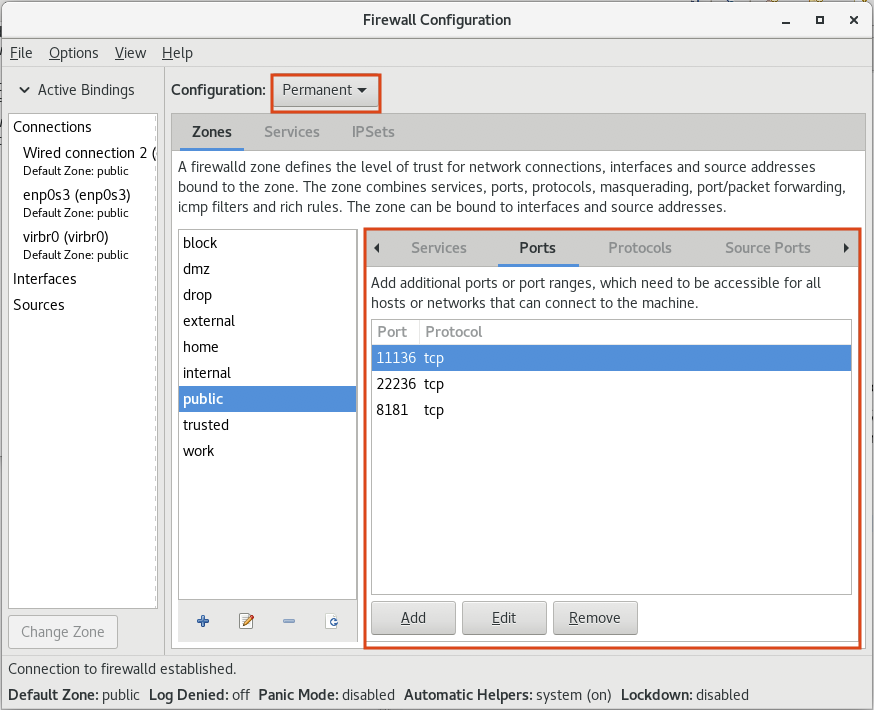
133 KiB
{kind=link}
177 KiB
Makefile
deleted
100644 → 0
demo/apsu-20150709/demo_notes.sv.txt
deleted
100644 → 0
demo/sdm-20150716/demo_notes.sv.txt
deleted
100644 → 0
dm_test_system_deployment_notes.txt
deleted
100644 → 0
getting_started/getting-started.md
0 → 100644
getting_started/gettingDataFromGlobus.md
0 → 100644
sphinx/Makefile
deleted
100644 → 0